Web抓取保护,如何防范网络爬虫抓取?
发布时间:2025-01-03 10:12:48 关键词:Web抓取保护
Web抓取保护,如何防范网络爬虫抓取?
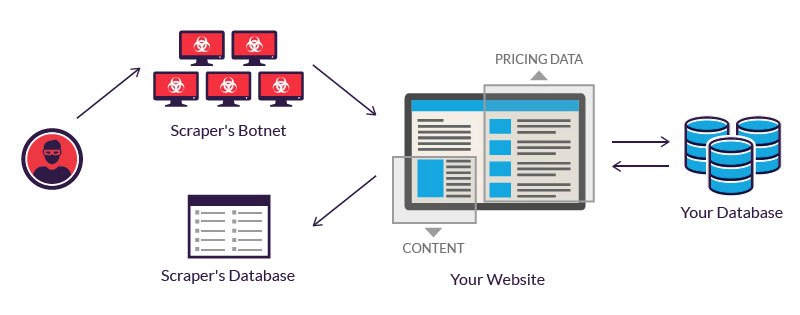
恶意爬虫机器人日益复杂,导致一些常见的安全措施无效。例如,无头浏览器机器人可以伪装成人类,因为它们在大多数缓解解决方案的雷达下飞行。
为了对抗恶意机器人操作员的进步,Imperva使用了粒度流量分析。它确保所有进入您网站的流量,无论是人类还是机器人,都是完全合法的。
该过程涉及因素的交叉验证,包括:
•HTML指纹——过滤过程始于对HTML标头的精细检查。这些可以提供线索,说明访问者是人类还是机器人,是恶意的还是安全的。将标头签名与一个不断更新的数据库进行比较,该数据库包含1000多万个已知变体。
•IP声誉——我们从所有针对客户的攻击中收集IP数据。来自有攻击历史的IP地址的访问会受到怀疑,更有可能受到进一步审查。
•行为分析——跟踪访问者与网站互动的方式可以揭示异常的行为模式,例如可疑的攻击性请求率和不合逻辑的浏览模式。这有助于识别冒充人类访客的机器人。
•渐进式挑战——我们使用一系列挑战,包括cookie支持和JavaScript执行,来过滤机器人并尽量减少误报。作为最后的手段,验证码挑战可以清除试图冒充人类的机器人。
猜你喜欢