什么是网页抓取?网络抓取工具和机器人
1、什么是网页抓取
网络抓取是使用机器人从网站中提取内容和数据的过程。
与仅复制屏幕上显示的像素的屏幕抓取不同,网络抓取提取底层HTML代码,并提取存储在数据库中的数据。然后,抓取器可以在其他地方复制整个网站内容。
网络抓取用于各种依赖数据收集的数字业务。合法用例包括:
•搜索引擎机器人抓取网站,分析其内容,然后对其进行排名。
•价格比较网站部署机器人,为联盟卖家网站自动获取价格和产品描述。
•市场研究公司使用抓取器从论坛和社交媒体中提取数据(例如,用于情绪分析)。
网络抓取也被用于非法目的,包括降低价格和盗窃受版权保护的内容。被爬虫攻击的在线实体可能会遭受严重的财务损失,特别是如果它是一家严重依赖竞争性定价模式或内容分发交易的企业。
2、网络抓取工具和机器人
网络抓取工具是经过编程的软件(即机器人),用于筛选数据库并提取信息。使用了各种各样的机器人类型,其中许多可以完全定制为:
•识别独特的HTML网站结构
•提取和转换内容
•存储抓取的数据
•从API中提取数据
由于所有抓取机器人都有相同的目的——访问网站数据——因此很难区分合法和恶意机器人。
也就是说,几个关键差异有助于区分两者。
1.合法的机器人被识别为它们所抓取的组织。例如,Googlebot在其HTTP标头中将自己标识为属于Google。相反,恶意机器人通过创建虚假的HTTP用户代理来冒充合法流量。
2.合法的机器人遵守网站的robot.txt文件,该文件列出了机器人可以访问的页面和不能访问的页面。另一方面,恶意抓取器会抓取网站,而不管网站运营商允许什么。
运行网络抓取机器人所需的资源是巨大的,以至于合法的抓取机器人运营商大量投资于服务器来处理提取的大量数据。
由于缺乏这样的预算,犯罪者通常会使用僵尸网络——地理上分散的计算机,感染了相同的恶意软件,并由一个中心位置控制。个人僵尸网络计算机所有者不知道他们的参与。受感染系统的综合力量使攻击者能够大规模抓取许多不同的网站。
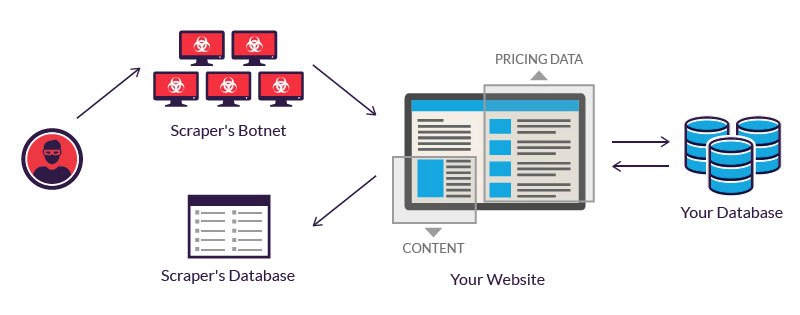
3、恶意网络抓取示例
当未经网站所有者许可提取数据时,网络抓取被认为是恶意的。两个最常见的用例是价格抓取和内容盗窃。
1)价格抓取
在价格抓取中,犯罪者通常使用僵尸网络来启动抓取机器人,以检查竞争对手的业务数据库。目标是获取定价信息,削弱竞争对手,促进销售。
在产品易于比较且价格在购买决策中起主要作用的行业中,攻击经常发生。价格掠夺的受害者可能包括旅行社、售票员和在线电子产品供应商。
例如,智能手机电子零售商经常成为目标,他们以相对一致的价格销售类似的产品。为了保持竞争力,他们有动力提供尽可能优惠的价格,因为客户通常会选择成本最低的产品。为了获得优势,供应商可以使用机器人不断抓取竞争对手的网站,并相应地立即更新自己的价格。
对于肇事者来说,成功的价格抓取可以使他们的报价在比较网站上突出显示,供客户用于研究和购买。与此同时,被淘汰的网站经常会出现客户和收入损失。
2)内容抓取
内容抓取包括从给定网站大规模窃取内容。典型的目标包括在线产品目录和依赖数字内容推动业务的网站。对于这些企业来说,内容抓取攻击可能是毁灭性的。
例如,在线本地商业目录在构建数据库内容方面投入了大量的时间、金钱和精力。刮擦可能会导致所有内容被释放到野外,用于垃圾邮件活动或转售给竞争对手。这些事件中的任何一个都可能影响企业的底线及其日常运营。
以下内容摘自Craigslist提交的一份投诉,详细介绍了其在内容抓取方面的经验。它强化了这种做法的破坏性:
“[内容抓取服务]每天都会向craigslist发送一大批数字机器人,复制和下载数百万craigslists用户广告的全文。[该服务]然后通过其所谓的‘数据馈送’,不加选择地将这些被盗用的列表提供给任何想以任何目的使用它们的公司。一些这样的‘客户’每月为这些内容支付高达2万美元的费用……”
根据该声明,抓取的数据被用于垃圾邮件和电子邮件欺诈等活动:
“[被告]然后从该数据库中收集craigslist用户的联系信息,并每天向craigslist-servers收集的地址发送数千封电子邮件……[这些邮件]在垃圾邮件正文中包含误导性的主题行和内容,旨在诱骗craigslists用户从使用craigslism的服务切换到使用[辩护人]的服务……”